by Kelly Rathje
This article was originally published in the Winter 2000 issue of the Expert Witness.
When we are asked to estimate a claimant’s potential future income (without- or with-accident) we rely on two types of data – data specific to the individual, such as the claimant’s tax returns, and statistical data concerning individuals “similar” to the plaintiff, such as information drawn from the Census.
When the plaintiff is part of a common class of victims, however, it is possible to rely on more sophisticated statistical techniques to assess the impact of the injurious act. Such classes of plaintiffs might include, for example, victims of chemical or radiation poisoning in a factory or residential area or victims of sexual or physical abuse at a school.
In these cases, economists can rely on a technique known as econometric modelling (see the accompanying article from this newsletter) to determine whether the average income of the class of victims differs significantly from the average income of a similar group chosen at random from the population.
The difference may be determined by specifying characteristics, common to both groups, and examining how these factors influence income. Any difference in income not attributable to the specified characteristics could be attributed to the incident, and thus the loss of income due to the incident may be determined.
To use this method, an economist would need to gather data, do some comparative statistical analysis, and then apply the econometric model. These steps are outlined below.
Data
The data for the claimant’s group is most commonly compiled from information provided by the individuals within that group. The comparison group, which is to represent a random sample from the population, can often be obtained from broad data sources such as the census.
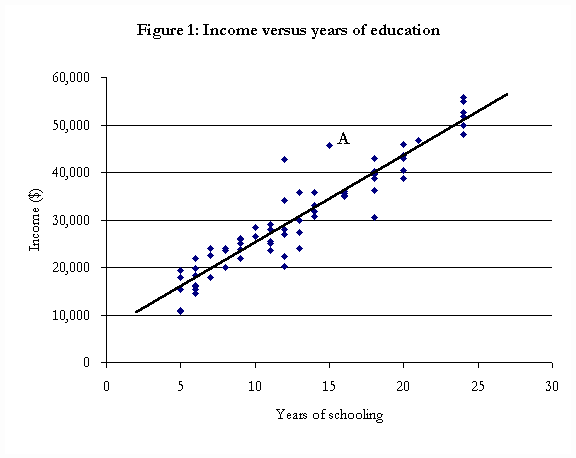
Using these sources, the economist would create two types of variables. The first of these are “numerical” variables; that is variables that can be measured using numerical scales. For example, if the economist is trying to identify the determinants of income, numerical variables might include age, years of education, and work experience.
The second set of variables, “dummy” variables, are variables that cannot be measured numerically. For example, these might include place of residence or sex of the individual. For example, if the economist wished to test the hypothesis that people in the Maritimes earned less than individuals in the rest of Canada (ROC), a variable might be created that divided the group between Maritimes and ROC.
Comparisons
Before any formal estimation is done, economists usually look at the raw data to see if any trends or relationships are present. Using the characteristics indicated above (age, place of residence, years of education, and current income), trends of interest to economists might be employment rates, average numbers of years of educational attainment, and average income levels for each group.
Econometric modelling
Using the characteristics outlined, an (econometric) equation is created to examine the factors that influence income. The equation, in its simplest form, might be as follows:
I = C + b1[age] + b2[maritimes] + b3[claimants]
What this equation predicts is that income, I, will be determined by the individual’s age, place of residence, membership either in or out of the “claimant” group, and a fixed factor, C. In this equation, “age” is a numerical variable – it might take values such as 25 or 47 years old, for example.
“Maritimes” and “claimants” are dummy variables. In this case, “Maritimes” takes the value 1 if the individual lives in the Maritimes and 0 if he or she lives in the ROC; and “claimants” takes the value 1 if the individual is one of the plaintiffs and 0 if he or she was chosen from the random sample of other individuals in the population.
Once the data set has been collected, and the form of the equation has been identified, statistical techniques are applied to the data to estimate the “best” values of b1, b2, and b3.
The data might suggest, for example, that the most likely relationship among the variables is:
I = 25,000 + 500[age]- 4,500[maritimes] – 20,000[claimants]
This indicates that for each year an individual ages, income increases by $500, on average; and that if the individual lives in the Maritimes, income will be, on average, $4,500 less than if that individual lives in the ROC. The above estimation also indicates that, on average, the claimant group will earn $20,000 less than average individuals in the population, all else being equal. For example, a 37-year-old, who lives in the Maritimes, and is not part of the claimant’s group would earn $39,000 (= 25,000 + 500[37] – 4,500[1] – 20,000[0]); and a 37-year-old, who lives in the Maritimes, and is a part of the claimant’s group would earn $19,000 (= 25,000 + 500[37] – 4,500[1] – 20,000[1]);
Now suppose the economist also has information on the employment status of each individual in both groups. The next step that may be undertaken is to estimate what an individual’s income would be given the above characteristics, but limiting the observations to employed individuals only. That is, the economist might control for employment status by including only observations at which the income is greater than zero. This would indicate how much of the difference in income, found in the first estimation, could be attributed to employment status. The resulting equation might be, for example:
I = 21,000 + 200[age] – 4,500[maritimes] – 12,000[claimants]
Given that I > 0
Recall from above, when considering both employed and unemployed individuals together, the equation indicated that the claimant’s group earned approximately $20,000 less than the random population. Now, controlling for employment, they are found to earn $12,000 less. This implies that $8,000 of the earnings gap between the plaintiff group and the general population can be explained by the higher unemployment rate of the former group.
Now suppose there is additional information regarding the education levels of the groups. The next logical step would be to add educational attainment as one of the explanatory variables. Thus, the equation would include the number of years of education, place of residence, age, and “claimant” status. This specification adds another explanatory factor to help predict income levels. Still controlling for employment status, the resulting equation might be:
I = 20,000 + 100[age]- 4,000[maritimes] + 2,000 [education] – 7,000[claimants]
Given that I > 0
This equation, given the known characteristics in this example, has the most explanatory power. It indicates to the economist that controlling for all the known variables, there still exists a difference in income of $7,000 between the claimants and an individual chosen at random from the general population, given that both individuals have the same characteristics.
Note, however, that this does not mean that the effect of the tortious act is, on average, $7,000 per year per claimant. First, remember that when no allowance was made for employment status or education, the average difference between the annual incomes of the claimants and members of the general population was $20,000. What the last equation predicts is that if we compare two individuals who have the same education and the same employment status, we will find that the “claimant” earns, on average, $7,000 less than the non-claimant. However, the effect of the tortious act may have been to increase the unemployment rates of the claimants and reduce their educational attainments (particularly if they were injured while they were minors). In that case, the $7,000 would represent the lower bound on the estimated impact of the injury.
Second, part of the income differential between claimants and non-claimants may be the result of factors that have not been taken into account in the equations. For example, assume that the claimants had all been harmed by the release of a toxic chemical. It might be that individuals who are susceptible to that chemical share some genetic factor that also reduces their abilities to earn income. If that genetic factor is not taken into account, the statistician may attribute the lower incomes of members of that group to the chemical when, in fact, that group would have earned lower incomes in any event.
Another drawback is that this method determines average incomes for the group, and thus, average differentials for the group. That is, the income differentials between the claimant group and the random group apply to the overall group, and not necessarily to each claimant. When the claimants are considered individually, the economist may find that some of the claimants are earning more than the average income predicted by the model; some are earning less income than the average income predicted by the model; and some are earning the same income the model predicted. However, on average, the group still has a reduction in earnings, when compared to individuals chosen at random from the population, with the otherwise same characteristics (other than the incident).
We were recently asked to determine whether there was economic evidence to support a claim that a group of individuals experienced a loss of income as a result of a common incident. We followed much of the same steps and methodology described here in determining: (i) whether an income differential existed; and (ii) the extent to which each of the known factors influence income. This methodology allowed a quantitative measure of the loss of income to be predicted, given the information provided by the group, and compared to a random sample of the population.

Kelly Rathje is a consultant with Economica and has a Master of Arts degree (in economics) from the University of Calgary.